

|
具身智能软硬件产业链
分享
+
下载
+
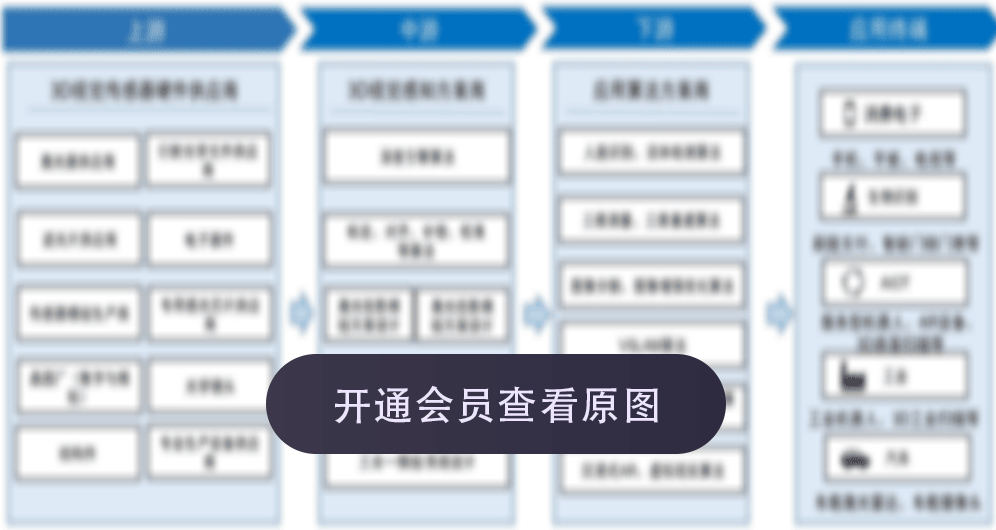
数据来源:中信建投证券,优必选招股书
最近更新: 2025-12-30
补充说明:1、E表示预测数据;2、*表示估计数据;
数据描述
具身智能的技术路径涵盖感知、决策、行动、反馈及软硬件协同等关键层面。感知环节依赖多元传感器构建环境信息采集体系,可见光相机、激光雷达等各司其职,稳定场景采用特定算法,复杂环境则需多 模态 大模型实现信息深度融合。决策层面,传统人工编程和专用算法难以适应动态环境,强化学习存在局限。 大模 型的应用带来突破,视觉语言动作模型(VLA)可将自然语言指令转化为动作,视觉语言导航模型(VLN)能 结合语言与视觉规划轨迹,未来多模态大模型与世界模型融合将进一步增强决策能力。行动模块负责指令 执行 ,其动作生成从调用预编算法逐步向端到端大模型直接推理升级,显著提升灵活性与精准度。反馈模块通 过多 层交互,实时监测各环节运行状态,优化系统整体性能。硬件上,机器人本体与控制装置构成实体基础, 软件 中间件如ROS虽实现硬件抽象与驱动,但在对接云端、边端大模型时存在兼容性问题。未来需通过技术 创新 实现软硬件深度协同,推动具身智能技术发展。