

|
2025-2040年中国人形机器人产业规模预测
分享
+
下载
+
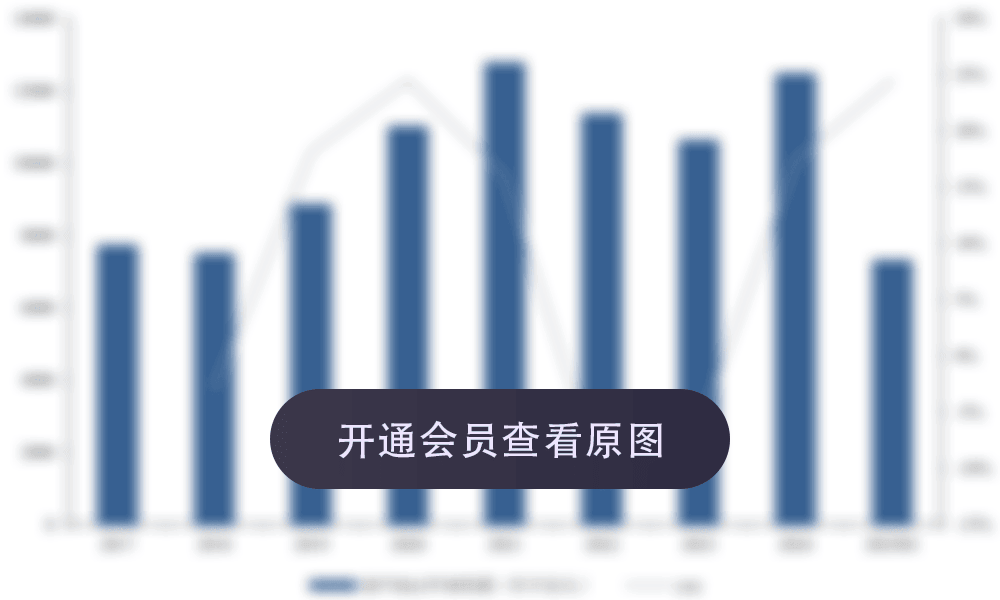
数据来源:国金证券研究所,亿欧智库
最近更新: 2026-01-04
补充说明:1、E表示预测数据;2、*表示估计数据;
数据描述
上,马斯克进一步对人形机器人的长期需求进行外推,认为人形机器人和人类的数量比例有望达到3:1-5:1,对应全球人形机器人保有量可达200-300亿台。
目前限制人形机器人大规模量产的重要因素是大脑进化。机器人逻辑架构由“大脑”+“小脑”+肢体组成,目前人形机器人“肢体”硬件方案趋于收敛,硬件发展整体走在软件之前。大模型是现阶段“大脑”的最佳解决方案,为人形机器人提供任务级交互、环境感知、任务规划和决策控制能力。伴随着AI大模型的迭代,机器人大脑实现产业实现跨越式发展,智能化程度有望提升。
非具身大模型:服务于人类,输出的内容是给人看或者给人读,更多还是在人机交互、内容生成等方面展现价值。这类模型输入模态是语言、图片和视频,输出模态是语言、图片和视频。具体又可分为:
语言大模型:以自然语言处理为核心,主要用于文本生成、机器翻译、情感分析等任务,代表模型如GPT系列。视觉大模型:以图像或视频数据处理为核心,主要应用于图像识别、目标检测与视频理解等领域,代表模型如Emu等。多模态大模型:融合文本、图像、音频、3D点云及各类传感器数据,实现跨模态理解与交互,代表模型包括Sora等。
具身大模型:服务于机器,其输出的内容是需要机器人能够理解、并最终要转化为具体可执行动作的控制指令,以机械臂为例,最终输出可能就是对电机的控制信号。具身大模型可分为自动驾驶大模型和机器人大模型,代表模型如Tesla FSD、谷歌RT2、智元机器人的GO-1等,具身大模型输入的是视觉、语言信号,输出的是三维物理世界的操作。